はじめに
今回の記事は正規表現についてざっくりとまとめたものです。次のようなことがわかります。
- 正規表現とはどういったものなのか
- いつ使うのか
- 読むにはどうしたらいいのか
逆に、以下については書いていません。
- アンカー、先読み、後読み
- 細かい文法
- オートマトンとの対応
- 各種言語での違い
今回はJavaScriptの正規表現を対象に話します。しかし、正規表現の基礎となる箇所は抑えられるはずです。
そもそも: 正規表現とは?
正規表現とは、一言でいうと「ワイルドカードのすごいやつ」です。例えば、ワイルドカードを含んだ「???駅」は「東京駅」「仙台駅」などとマッチします。乱暴にいえば、「???駅」を書きやすくしたものが正規表現です。
正規表現の代表的な使い方は以下のとおりです。
- 文字列がその正規表現を満たすかチェックする
- 文字列のうち、その正規表現にマッチする箇所を置き換える
- 文字列のうち、その正規表現にマッチする箇所を検索して抜き出す
正規表現は「文字列の集合を表せる」ので、かなり色んなところで使われています。エディタの検索で使えることも多いです。ぜひ覚えましょう。
例: 「ファイル名はなんでも良く、拡張子が.html」という文字列集合を表す正規表現
正規表現の例をいくつか紹介していきます。
たとえば、「ファイル名はなんでも良く、拡張子が.html」という文字列の集合(index.html や article.html など)を表す正規表現は次のようになります。
.+\.html
少しだけこの正規表現の解説を書きます(読み飛ばして次へ行っても構いません)。正規表現において.は特別な意味を持ち、任意の一文字*1を表しています。+も同様に特別な意味があり、直前の文字が1回以上繰り返されることを表します。つまり、.+は長さ1文字以上の任意の文字列を表します。後ろに続いている\.htmlはそのまま .html という文字列です。まとめると、この正規表現は「長さが1以上の任意の文字列の後ろに .htmlがついている文字列」を表しています。
例: .ts / .tsx / .js / .jsx のどれかと一致する正規表現
もう一つ例を挙げます。たとえば、「.ts」「.tsx」「.js」「.jsx」の4つを表す正規表現は次のように書けます。
\.[tj]sx?
こちらも少し解説します(読み飛ばして次へ行っても構いません)。まず、先ほども解説しましたが. は正規表現において特殊な文字なので、バックスラッシュでエスケープしてあります(\.)。そして、次の[tj]は、カッコ内の文字列のどれか1つを意味します。そして、最後についている ? は正規表現において特別な意味があり、直前の文字がなくても構わないことを示します。まとめると、この正規表現は「. のうしろが t / j で、そのあとに s が続き、x はあってもなくてもよい文字列」を表しています。先ほどの4つはちょうどこれを満たしています。
脱線: 「正規表現」という名称について
すこし脱線して、「正規表現」という名称について解説します。なぜ「正規表現」なのかというと、正規言語と関係しています。正規言語というのは、「ある正規表現にマッチする文字列の集合」を意味します。正規言語を表す文字列だから正規表現と呼ぶわけです(正規言語をなぜ「正規」言語と呼称するのかはちょっとわかりません。なんでですかね)。ただし、プログラミング言語が扱う正規表現は正規言語を表していません。なぜかというと、プログラミング中に扱う正規表現は、本来の正規表現ではなくプログラミングする上で使いやすいよう拡張されているためです。正規表現とは、「正規言語を表すもの」を指すので、プログラミング言語の「正規表現」は厳密には正規表現ではありません。
regexper.com を使おう
さて、前章で正規表現についてはなんとなくわかっていただけたと思います。しかし、まだ読むのは大変ですよね。そんなときは、正規表現をビジュアライズしてくれるツールをぜひ使ってみてください。
そのツールが regexper.com です。regexper.com は入力された正規表現をダイヤグラムにして表示してくれます。僕も複雑な正規表現を読むときはお世話になることが多いです。
例: 電話番号を表す正規表現
たとえば次の電話番号を表した正規表現は、次のようなダイヤグラムになります。
\d{3}-\d{4}-\d{4}
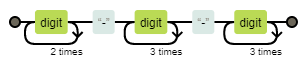
上の図は、正規表現が
- 数字を3回繰り返す
- ハイフン
- 数字4つ
- ハイフン
- 数字4つ
という文字列にマッチすることを表しています。このように、図を見ればどのような正規表現なのかが一発でわかります。
では、先の章で出した「.ts / .tsx / .js / .jsx のいずれかにマッチする正規表現」も regexper.com にかけてみます。
\.[tj]sx?
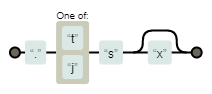
いかがでしょうか?正規表現そのものを読むのは苦痛でも、図に落とし込まれたらだいぶ楽ではないでしょうか。
ちなみに、VSCode には同じように正規表現を図示してくれる拡張機能があります。ぜひ試してみてください。
パーサーコンビネーターの紹介
実は、パーサーコンビネーターという正規表現の上位互換のようなものが存在します。パーサーコンビネーターは正規表現より可読性に優れ、しかも正規表現よりも表現力が高いです。構文解析をしたいときによく出てきます。
パーサーコンビネーターは、その名の通り「パーサー」を組み合わせてより大きいパーサーを作っていくものです。たとえば、「任意の文字列」に一致するパーサーと、「.htmlという文字列」に一致するパーサーを組み合わせて、「(任意の文字列).html」にマッチするパーサーを書けます。
const {seq: sequence, string, letters} = Parsimmon; // sequence, string はパーサーを生成する関数、letters は任意の文字列にマッチするパーサー const FileMatcher = sequence(letters, string('.html')); // (任意の文字列).html にマッチするパーサー FileMatcher.tryParse('index.html'); // きちんとパースできる FileMatcher.tryParse('picture.jpeg'); // 構文を満たしていないのでパースできない
同じことをする正規表現はこちらになります。
.+\.html
正規表現を知らない人はこの正規表現を読めないと思いますが、パーサーコンビネーターの方は知らなくともなんとなく意図が伝わるかと思います。このように、小さいパーサーを組み合わせながら構築していくので、正規表現より可読性が高いことが多いです。
パーサーコンビネーターは木構造をパースできる
ほかに、パーサーコンビネーターでは書けて、正規表現では書けないものもあります。例えば再帰構造が一例です。HTMLやXMLのような木構造をパーサーコンビネーターでは書くことができます。
簡易的な HTML の構文を、パーサーコンビネーターライブラリ Parsimmon を用いて書いてみます。なんとなくパーサーコンビネーターの雰囲気を感じ取っていただけるかと思います。ここではライブラリの詳しい解説はしません。
const {seq: sequence, string, letters} = Parsimmon; const HTMLLang = Parsimmon.createLanguage({ StartTag: () => { return sequence(string('<'), letters, string('>')); // <body> や <head> のような文字列にマッチする }, EndTag: () => { return sequence(string('</'), letters, string('>')); // </body> や </head> のような文字列にマッチする }, Element: ({StartTag, EndTag, Element}) => { return sequence(StartTag, EndTag).or(sequence(StartTag, Element, EndTag)); // {開始タグ}{終了タグ} という文字列か、 {開始タグ}{要素}{終了タグ}にマッチする }, }); HTMLLang.Element.tryParse('<p><b><span></span></b></p>'); // きちんとパースできる HTMLLang.Element.tryParse('<p><b><span></p></b></span>'); // 構文を満たしていないのでパースできない
正規表現では同じことをしようとしてもできません。
このように、パーサライブラリは正規表現より可読性が高いうえ、表現力も高いです。複雑な正規表現が必要なときはパーサライブラリもぜひ検討してみてください。
*1:厳密にはちょっと違います